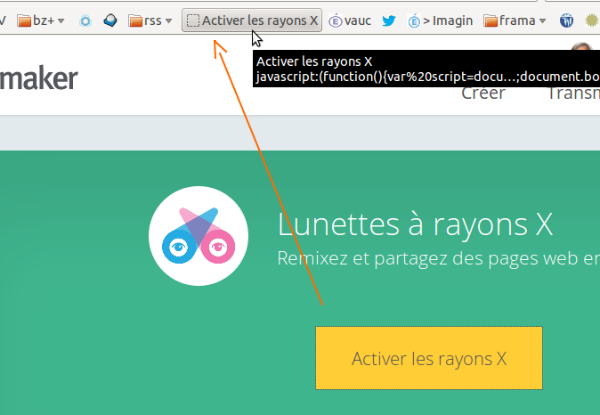
Le mois dernier, WhatsApp a publié une nouvelle politique de confidentialité avec cette injonction : acceptez ces nouvelles conditions, ou supprimez WhatsApp de votre smartphone. La transmission de données privées à la maison-mère Facebook a suscité pour WhatsApp un retour de bâton retentissant et un nombre significatif d’utilisateurs et utilisatrices a migré vers d’autres applications, en particulier Signal.
Cet épisode parmi d’autres dans la guerre des applications de communication a suscité quelques réflexions plus larges sur la capture des utilisateurs et utilisatrices par des entreprises qui visent selon Rohan Kumar à nous « domestiquer »…
Article original : WhatsApp and the domestication of users, également disponible sur la capsule gemini de l’auteur.
Traduction Framalang : Bromind, chloé, fabrice, françois, goofy, jums, Samailan, tykayn
WhatsApp et la domestication des utilisateurs
par Rohan Kumar
![]() Je n’ai jamais utilisé WhatsApp et ne l’utiliserai jamais. Et pourtant j’éprouve le besoin d’écrire un article sur WhatsApp car c’est une parfaite étude de cas pour comprendre une certaine catégorie de modèles commerciaux : la « domestication des utilisateurs ».
Je n’ai jamais utilisé WhatsApp et ne l’utiliserai jamais. Et pourtant j’éprouve le besoin d’écrire un article sur WhatsApp car c’est une parfaite étude de cas pour comprendre une certaine catégorie de modèles commerciaux : la « domestication des utilisateurs ».
La domestication des utilisateurs est, selon moi, l’un des principaux problèmes dont souffre l’humanité et il mérite une explication détaillée.
Cette introduction générale étant faite, commençons.
L’ascension de Whatsapp
Pour les personnes qui ne connaissent pas, WhatsApp est un outil très pratique pour Facebook car il lui permet de facilement poursuivre sa mission principale : l’optimisation et la vente du comportement humain (communément appelé « publicité ciblée »). WhatsApp a d’abord persuadé les gens d’y consentir en leur permettant de s’envoyer des textos par Internet, chose qui était déjà possible, en associant une interface simple et un marketing efficace. L’application s’est ensuite développée pour inclure des fonctionnalités comme les appels vocaux et vidéos gratuits. Ces appels gratuits ont fait de WhatsApp une plate-forme de communication de référence dans de nombreux pays.
WhatsApp a construit un effet de réseau grâce à son système propriétaire incompatible avec d’autres clients de messagerie instantanée : les utilisateurs existants sont captifs car quitter WhatsApp signifie perdre la capacité de communiquer avec les utilisateurs de WhatsApp. Les personnes qui veulent changer d’application doivent convaincre tous leurs contacts de changer aussi ; y compris les personnes les moins à l’aise avec la technologie, celles qui avaient déjà eu du mal à apprendre à se servir de WhatsApp.
Dans le monde de WhatsApp, les personnes qui souhaitent rester en contact doivent obéir aux règles suivantes :
• Chacun se doit d’utiliser uniquement le client propriétaire WhatsApp pour envoyer des messages ; développer des clients alternatifs n’est pas possible.
• Le téléphone doit avoir un système d’exploitation utilisé par le client. Les développeurs de WhatsApp ne développant que pour les systèmes d’exploitation les plus populaires, le duopole Android et iOS en sort renforcé.
• Les utilisateurs dépendent entièrement des développeurs de WhatsApp. Si ces derniers décident d’inclure des fonctionnalités hostiles dans l’application, les utilisateurs doivent s’en contenter. Ils ne peuvent pas passer par un autre serveur ou un autre client de messagerie sans quitter WhatsApp et perdre la capacité à communiquer avec leurs contacts WhatsApp.
La domestication des utilisateurs
WhatsApp s’est développé en piégeant dans son enclos des créatures auparavant libres, et en changeant leurs habitudes pour créer une dépendance à leurs maîtres. Avec le temps, il leur est devenu difficile voire impossible de revenir à leur mode de vie précédent. Ce processus devrait vous sembler familier : il est étrangement similaire à la domestication des animaux. J’appelle ce type d’enfermement propriétaire « domestication des utilisateurs » : la suppression de l’autonomie des utilisateurs, pour les piéger et les mettre au service du fournisseur.
J’ai choisi cette métaphore car la domestication animale est un processus graduel qui n’est pas toujours volontaire, qui implique typiquement qu’un groupe devienne dépendant d’un autre. Par exemple, nous savons que la domestication du chien a commencé avec sa sociabilisation, ce qui a conduit à une sélection pas totalement artificielle promouvant des gènes qui favorisent plus l’amitié et la dépendance envers les êtres humains1.
Qu’elle soit délibérée ou non, la domestication des utilisateurs suit presque toujours ces trois mêmes étapes :
1. Un haut niveau de dépendance des utilisateurs envers un fournisseur de logiciel
2. Une incapacité des utilisateurs à contrôler le logiciel, via au moins une des méthodes suivantes :
2.1. Le blocage de la modification du logiciel
2.2. Le blocage de la migration vers une autre plate-forme
3. L’exploitation des utilisateurs désormais captifs et incapables de résister.
L’exécution des deux premières étapes a rendu les utilisateurs de WhatsApp vulnérables à la domestication. Avec ses investisseurs à satisfaire, WhatsApp avait toutes les raisons d’implémenter des fonctionnalités hostiles, sans subir aucune conséquence. Donc, évidemment, il l’a fait.
La chute de WhatsApp
La domestication a un but : elle permet à une espèce maîtresse d’exploiter les espèces domestiquées pour son propre bénéfice. Récemment, WhatsApp a mis à jour sa politique de confidentialité pour permettre le partage de données avec sa maison mère, Facebook. Les personnes qui avaient accepté d’utiliser WhatsApp avec sa précédente politique de confidentialité avaient donc deux options : accepter la nouvelle politique ou perdre l’accès à WhatsApp. La mise à jour de la politique de confidentialité est un leurre classique : WhatsApp a appâté et ferré ses utilisateurs avec une interface élégante et une impression de confidentialité, les a domestiqués pour leur ôter la capacité de migrer, puis est revenu sur sa promesse de confidentialité avec des conséquences minimes. Chaque étape de ce processus a permis la suivante ; sans domestication, il serait aisé pour la plupart des utilisateurs de quitter l’application sans douleur.
Celles et ceux parmi nous qui sonnaient l’alarme depuis des années ont connu un bref moment de félicité sadique quand le cliché à notre égard est passé de « conspirationnistes agaçants et paranoïaques » à simplement « agaçants ».
Une tentative de dérapage contrôlé
L’opération de leurre et de ferrage a occasionné une réaction contraire suffisante pour qu’une minorité significative d’utilisateurs migre ; leur nombre a été légèrement supérieur la quantité négligeable que WhatsApp attendait probablement. En réponse, WhatsApp a repoussé le changement et publié la publicité suivante :

Cette publicité liste différentes données que WhatsApp ne collecte ni ne partage. Dissiper des craintes concernant la collecte de données en listant les données non collectées est trompeur. WhatsApp ne collecte pas d’échantillons de cheveux ou de scans rétiniens ; ne pas collecter ces informations ne signifie pas qu’il respecte la confidentialité parce que cela ne change pas ce que WhatsApp collecte effectivement.
Dans cette publicité WhatsApp nie conserver « l’historique des destinataires des messages envoyés ou des appels passés ». Collecter des données n’est pas la même chose que « conserver l’historique » ; il est possible de fournir les métadonnées à un algorithme avant de les jeter. Un modèle peut alors apprendre que deux utilisateurs s’appellent fréquemment sans conserver l’historique des métadonnées de chaque appel. Le fait que l’entreprise ait spécifiquement choisi de tourner la phrase autour de l’historique implique que WhatsApp soit collecte déjà cette sorte de données soit laisse la porte ouverte afin de les collecter dans le futur.
Une balade à travers la politique de confidentialité réelle de WhatsApp du moment (ici celle du 4 janvier) révèle qu’ils collectent des masses de métadonnées considérables utilisées pour le marketing à travers Facebook.
Liberté logicielle
Face à la domestication des utilisateurs, fournir des logiciels qui aident les utilisateurs est un moyen d’arrêter leur exploitation. L’alternative est simple : que le service aux utilisateurs soit le but en soi.
Pour éviter d’être contrôlés par les logiciels, les utilisateurs doivent être en position de contrôle. Les logiciels qui permettent aux utilisateurs d’être en position de contrôles sont appelés logiciels libres. Le mot « libre » dans ce contexte a trait à la liberté plutôt qu’au prix2. La liberté logicielle est similaire au concept d’open-source, mais ce dernier est focalisé sur les bénéfices pratiques plutôt qu’éthiques. Un terme moins ambigu qui a trait naturellement à la fois à la gratuité et l’open-source est FOSS3.
D’autres ont expliqué les concepts soutenant le logiciel libre mieux que moi, je n’irai pas dans les détails. Cela se décline en quatre libertés essentielles :
- la liberté d’exécuter le programme comme vous le voulez, quel que soit le but
- la liberté d’étudier comment le programme fonctionne, et de le modifier à votre souhait
- la liberté de redistribuer des copies pour aider d’autres personnes
- la liberté de distribuer des copies de votre version modifiée aux autres
Gagner de l’argent avec des FOSS
L’objection la plus fréquente que j’entends, c’est que gagner de l’argent serait plus difficile avec le logiciel libre qu’avec du logiciel propriétaire.
Pour gagner de l’argent avec les logiciels libres, il s’agit de vendre du logiciel comme un complément à d’autres services plus rentables. Parmi ces services, on peut citer la vente d’assistance, la personnalisation, le conseil, la formation, l’hébergement géré, le matériel et les certifications. De nombreuses entreprises utilisent cette approche au lieu de créer des logiciels propriétaires : Red Hat, Collabora, System76, Purism, Canonical, SUSE, Hashicorp, Databricks et Gradle sont quelques noms qui viennent à l’esprit.
L’hébergement n’est pas un panier dans lequel vous avez intérêt à déposer tous vos œufs, notamment parce que des géants comme Amazon Web Service peuvent produire le même service pour un prix inférieur. Être développeur peut donner un avantage dans des domaines tels que la personnalisation, le support et la formation ; cela n’est pas aussi évident en matière d’hébergement.
Les logiciels libres ne suffisent pas toujours
Le logiciel libre est une condition nécessaire mais parfois insuffisante pour établir une immunité contre la domestication. Deux autres conditions impliquent de la simplicité et des plates-formes ouvertes.
Simplicité
Lorsqu’un logiciel devient trop complexe, il doit être maintenu par une vaste équipe. Les utilisateurs qui ne sont pas d’accord avec un fournisseur ne peuvent pas facilement dupliquer et maintenir une base de code de plusieurs millions de lignes, surtout si le logiciel en question contient potentiellement des vulnérabilités de sécurité. La dépendance à l’égard du fournisseur peut devenir très problématique lorsque la complexité fait exploser les coûts de développement ; le fournisseur peut alors avoir recours à la mise en œuvre de fonctionnalités hostiles aux utilisateurs pour se maintenir à flot.
Un logiciel complexe qui ne peut pas être développé par personne d’autre que le fournisseur crée une dépendance, première étape vers la domestication de l’utilisateur. Cela suffit à ouvrir la porte à des développements problématiques.
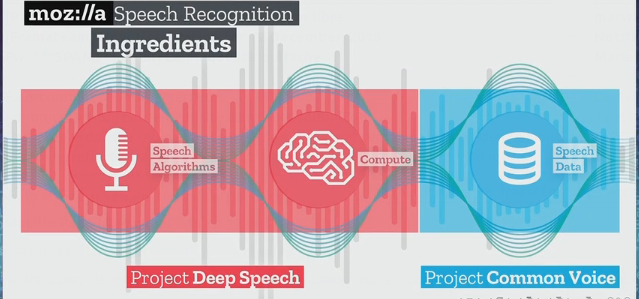
Étude de cas : Mozilla et le Web
Mozilla était une lueur d’espoir dans la guerre des navigateurs, un espace dominé par la publicité, la surveillance et le verrouillage par des distributeurs. Malheureusement, le développement d’un moteur de navigation est une tâche monumentale, assez difficile pour qu’Opera et Microsoft abandonnent leur propre moteur et s’équipent de celui de Chromium. Les navigateurs sont devenus bien plus que des lecteurs de documents : ils ont évolué vers des applications dotées de propres technologies avec l’accélération GPU, Bluetooth, droits d’accès, énumération des appareils, codecs de médias groupés, DRM4, API d’extension, outils de développement… la liste est longue. Il faut des milliards de dollars par an pour répondre aux vulnérabilités d’une surface d’attaque aussi massive et suivre des standards qui se développent à un rythme tout aussi inquiétant. Ces milliards doivent bien venir de quelque part.
Mozilla a fini par devoir faire des compromis majeurs pour se maintenir à flot. L’entreprise a passé des contrats de recherche avec des sociétés manifestement hostiles aux utilisateurs et a ajouté au navigateur des publicités (et a fait machine arrière) et des bloatwares, comme Pocket, ce logiciel en tant que service partiellement financé par la publicité. Depuis l’acquisition de Pocket (pour diversifier ses sources de revenus), Mozilla n’a toujours pas tenu ses promesses : mettre le code de Pocket en open-source, bien que les clients soient passés en open-source, le code du serveur reste propriétaire. Rendre ce code open-source, et réécrire certaines parties si nécessaire serait bien sûr une tâche importante en partie à cause de la complexité de Pocket.
Les navigateurs dérivés importants comme Pale Moon sont incapables de suivre la complexité croissante des standards modernes du Web tels que les composants web (Web Components). En fait, Pale Moon a récemment dû migrer son code hors de GitHub depuis que ce dernier a commencé à utiliser des composants Web. Il est pratiquement impossible de commencer un nouveau navigateur à partir de zéro et de rattraper les mastodontes qui ont fonctionné avec des budgets annuels exorbitants pendant des décennies. Les utilisateurs ont le choix entre le moteur de navigation développé par Mozilla, celui d’une entreprise publicitaire (Blink de Google) ou celui d’un fournisseur de solutions monopolistiques (WebKit d’Apple). A priori, WebKit ne semble pas trop mal, mais les utilisateurs seront impuissants si jamais Apple décide de faire marche arrière.
Pour résumer : la complexité du Web a obligé Mozilla, le seul développeur de moteur de navigation qui déclare être « conçu pour les gens, pas pour l’argent », à mettre en place des fonctionnalités hostiles aux utilisateurs dans son navigateur. La complexité du Web a laissé aux utilisateurs un choix limité entre trois grands acteurs en conflit d’intérêts, dont les positions s’enracinent de plus en plus avec le temps.
Attention, je ne pense pas que Mozilla soit une mauvaise organisation ; au contraire, c’est étonnant qu’ils soient capables de faire autant, sans faire davantage de compromis dans un système qui l’exige. Leur produit de base est libre et open-source, et des composants externes très légèrement modifiés suppriment des anti-fonctionnalités.
Plates-formes ouvertes
Pour éviter qu’un effet de réseau ne devienne un verrouillage par les fournisseurs, les logiciels qui encouragent naturellement un effet de réseau doivent faire partie d’une plate-forme ouverte. Dans le cas des logiciels de communication/messagerie, il devrait être possible de créer des clients et des serveurs alternatifs qui soient compatibles entre eux, afin d’éviter les deux premières étapes de la domestication de l’utilisateur.
Étude de cas : Signal
Depuis qu’un certain vendeur de voitures a tweeté « Utilisez Signal », un grand nombre d’utilisateurs ont docilement changé de messagerie instantanée. Au moment où j’écris ces lignes, les clients et les serveurs Signal sont des logiciels libres et open-source, et utilisent certains des meilleurs algorithmes de chiffrement de bout en bout qui existent ; cependant, je ne suis pas fan.
Bien que les clients et les serveurs de Signal soient des logiciels libres et gratuits, Signal reste une plate-forme fermée. Le cofondateur de Signal, Moxie Marlinspike, est très critique à l’égard des plates-formes ouvertes et fédérées. Il décrit dans un article de blog les raisons pour lesquelles Signal reste une plate-forme fermée5. Cela signifie qu’il n’est pas possible de développer un serveur alternatif qui puisse être supporté par les clients Signal, ou un client alternatif qui supporte les serveurs Signal. La première étape de la domestication des utilisateurs est presque achevée.
Outre qu’il n’existe qu’un seul client et qu’un seul serveur, il n’existe qu’un seul fournisseur de serveur Signal : Signal Messenger LLC. La dépendance des utilisateurs vis-à-vis de ce fournisseur de serveur central leur a explosé au visage, lors de la récente croissance de Signal qui a provoqué des indisponibilités de plus d’une journée, mettant les utilisateurs de Signal dans l’incapacité d’envoyer des messages, jusqu’à ce que le fournisseur unique règle le problème.
Certains ont quand même essayé de développer des clients alternatifs : un fork Signal appelé LibreSignal a tenté de faire fonctionner Signal sur des systèmes Android respectueux de la vie privée, sans les services propriétaires Google Play. Ce fork s’est arrêté après que Moxie eut clairement fait savoir qu’il n’était pas d’accord avec une application tierce utilisant les serveurs Signal. La décision de Moxie est compréhensible, mais la situation aurait pu être évitée si Signal n’avait pas eu à dépendre d’un seul fournisseur de serveurs.
Si Signal décide de mettre à jour ses applications pour y inclure une fonction hostile aux utilisateurs, ces derniers seront tout aussi démunis qu’ils le sont actuellement avec WhatsApp. Bien que je ne pense pas que ce soit probable, la plate-forme fermée de Signal laisse les utilisateurs vulnérables à leur domestication.
Même si je n’aime pas Signal, je l’ai tout de même recommandé à mes amis non-techniques, parce que c’était le seul logiciel de messagerie instantanée assez privé pour moi et assez simple pour eux. S’il y avait eu la moindre intégration à faire (création de compte, ajout manuel de contacts, etc.), un de mes amis serait resté avec Discord ou WhatsApp. J’ajouterais bien quelque chose de taquin comme « tu te reconnaîtras » s’il y avait la moindre chance pour qu’il arrive aussi loin dans l’article.
Réflexions
Les deux études de cas précédentes – Mozilla et Signal – sont des exemples d’organisations bien intentionnées qui rendent involontairement les utilisateurs vulnérables à la domestication. La première présente un manque de simplicité mais incarne un modèle de plate-forme ouverte. La seconde est une plate-forme fermée avec un degré de simplicité élevé. L’intention n’entre pas en ligne de compte lorsqu’on examine les trois étapes et les contre-mesures de la domestication des utilisateurs.
@paulsnar@mastodon.technology a souligné un conflit potentiel entre la simplicité et les plates-formes ouvertes :
j’ai l’impression qu’il y a une certaine opposition entre simplicité et plates-formes ouvertes ; par exemple Signal est simple précisément parce que c’est une plate-forme fermée, ou du moins c’est ce qu’explique Moxie. À l’inverse, Matrix est superficiellement simple, mais le protocole est en fait (à mon humble avis) assez complexe, précisément parce que c’est une plate-forme ouverte.
Je n’ai pas de réponse simple à ce dilemme. Il est vrai que Matrix est extrêmement complexe (comparativement à des alternatives comme IRC ou même XMPP), et il est vrai qu’il est plus difficile de construire une plate-forme ouverte. Cela étant dit, il est certainement possible de maîtriser la complexité tout en développant une plate-forme ouverte : Gemini, IRC et le courrier électronique en sont des exemples. Si les normes de courrier électronique ne sont pas aussi simples que Gemini ou IRC, elles évoluent lentement ; cela évite aux implémentations de devoir rattraper le retard, comme c’est le cas pour les navigateurs Web ou les clients/serveurs Matrix.
Tous les logiciels n’ont pas besoin de brasser des milliards. La fédération permet aux services et aux réseaux comme le Fediverse et XMPP de s’étendre à un grand nombre d’utilisateurs sans obliger un seul léviathan du Web à vendre son âme pour payer la facture. Bien que les modèles commerciaux anti-domestication soient moins rentables, ils permettent encore la création des mêmes technologies qui ont été rendues possibles par la domestication des utilisateurs. Tout ce qui manque, c’est un budget publicitaire ; la plus grande publicité que reçoivent certains de ces projets, ce sont de longs billets de blog non rémunérés.
Peut-être n’avons-nous pas besoin de rechercher la croissance à tout prix et d’essayer de « devenir énorme ». Peut-être pouvons-nous nous arrêter, après avoir atteint une durabilité et une sécurité financière, et permettre aux gens de faire plus avec moins.
Notes de clôture
Avant de devenir une sorte de manifeste, ce billet se voulait une version étendue d’un commentaire que j’avais laissé suite à un message de Binyamin Green sur le Fediverse.
J’avais décidé, à l’origine, de le développer sous sa forme actuelle pour des raisons personnelles. De nos jours, les gens exigent une explication approfondie chaque fois que je refuse d’utiliser quelque chose que « tout le monde » utilise (WhatsApp, Microsoft Office, Windows, macOS, Google Docs…).
Puis, ils et elles ignorent généralement l’explication, mais s’attendent quand même à en avoir une. La prochaine fois que je les rencontrerai, ils auront oublié notre conversation précédente et recommenceront le même dialogue. Justifier tous mes choix de vie en envoyant des assertions logiques et correctes dans le vide – en sachant que tout ce que je dis sera ignoré – est un processus émotionnellement épuisant, qui a fait des ravages sur ma santé mentale ces dernières années ; envoyer cet article à mes amis et changer de sujet devrait me permettre d’économiser quelques cheveux gris dans les années à venir.
Cet article s’appuie sur des écrits antérieurs de la Free Software Foundation, du projet GNU et de Richard Stallman. Merci à Barna Zsombor de m’avoir fait de bon retours sur IRC.

Mosaïque romaine, Orphée apprivoisant les animaux, photo par mharrsch, licence CC BY-NC-SA 2.0






 Bonjour, Parisien, 45 ans, je suis impliqué dans le projet Mozilla depuis pratiquement sa création et je travaille à plein temps pour Mozilla depuis 11 ans. De formation plutôt économique et linguistique, j’ai longtemps travaillé sur l’
Bonjour, Parisien, 45 ans, je suis impliqué dans le projet Mozilla depuis pratiquement sa création et je travaille à plein temps pour Mozilla depuis 11 ans. De formation plutôt économique et linguistique, j’ai longtemps travaillé sur l’


 Lorsque les médias nous ont révélé que des personnalités comme le PDG de Facebook Mark Zuckerberg et le directeur du FBI James Comey masquaient leurs webcams, nous avons été amenés à nous demander si nous ne devrions pas tous en faire autant. Mettre un post-it ou un bout de sparadrap sur la caméra peut vous donner l’impression que vous gardez le contrôle en vous protégeant contre l’espionnage d’un pirate. C’est vrai, tant que votre webcam est masquée, on ne peut pas vous voir, mais est-ce une protection efficace pour votre sécurité ?
Lorsque les médias nous ont révélé que des personnalités comme le PDG de Facebook Mark Zuckerberg et le directeur du FBI James Comey masquaient leurs webcams, nous avons été amenés à nous demander si nous ne devrions pas tous en faire autant. Mettre un post-it ou un bout de sparadrap sur la caméra peut vous donner l’impression que vous gardez le contrôle en vous protégeant contre l’espionnage d’un pirate. C’est vrai, tant que votre webcam est masquée, on ne peut pas vous voir, mais est-ce une protection efficace pour votre sécurité ?


 Avez-vous atterri ici en recherchant des conseils sur la meilleure manière de contribuer à l’open source ? Il y a des milliers d’histoires de ce genre sur Internet, n’est-ce pas ?
Avez-vous atterri ici en recherchant des conseils sur la meilleure manière de contribuer à l’open source ? Il y a des milliers d’histoires de ce genre sur Internet, n’est-ce pas ?











![Un noob derrière son PC se demande : « Tiens, et si j'essayais la commande rm -rf /* en root ?! » Réponse acceptable : « Attention : vous êtes sur le point de supprimer tous les fichiers de votre système. Probabilité de perdre tout = 100%. Risque de pétage de plomb élevé. Vous allez faire une connerie. Sérieux, ne faites pas ça. Êtes-vous sûr de vouloir commettre un suicide informatique ? [o, N] » Réponse inacceptable : « Plutôt mourir (enfin… tu vois ce que je veux dire). »](https://framablog.org/wp-content/uploads/2015/03/dm_002_10.png)